|
I am a full-time Applied Scientist at Adobe Firefly working on image and video diffusion models. I finished my Ph.D. in in 2024, from the Center for Research in Computer Vision (CRCV), University of Central Florida (UCF), advised by Prof. Mubarak Shah. My Ph.D. dissertation was about Video Understanding and Self-Supervised Learning.
|

|
 Email: ishandave95(a)gmail.com
Email: ishandave95(a)gmail.com
 Github
Github
Updates2025
Dec'25: A First author work "CreativeVR" released: state-of-the-art video restoration model
Oct'25: My led work "Generative Upscaler" is shipped as the default upscaler in the Photoshop 💥 Sep'25: A paper "Finegrained Video Retrieval" accepted at NeurIPS 2025 Jun'25: A paper "GT-Loc" accepted at ICCV 2025: Oral presentation! (Top 0.5% papers) Apr'25: A paper "ALBAR" accepted at ICLR 2025 Jan'25: Started full-time at Adobe Firefly, Seattle, WA 2024
Oct'24: Successfully defended my Ph.D dissertation!
Aug'24: SPAct Patent Approved! my first patent as the primary inventor 💥 Jul'24: 2 First author papers accepted at ECCV 2024: Oral presentation! (Top 3% papers)💥💥 Jun'24: Selected as Outstanding Reviewer of CVPR 2024! (top 2% among 10,000 reviewers)🥇 May'24: Started internship at Apple, Cupertino, CA 2023
Dec'23: A First author paper "No More Shortcuts" accepted to AAAI 2024 💥
Jul'23: A First author paper "Event-TransAct" accepted at IROS 2023 💥 Jul'23: A paper "TeD-SPAD" accepted at ICCV 2023 May'23: Started summer internship at Adobe, San Jose, CA Mar'23: A First author paper "TimeBalance" accepted to CVPR 2023 💥 Jan'23: A paper "TransVisDrone" accepted at ICRA 2023 2022
May'22: Started summer internship at Adobe, USA (remote- Florida)
Mar'22: A First author paper "TCLR" accepted to CVIU 2022 💥 Mar'22: A First author paper "SPAct" accepted to CVPR 2022 💥 2021 & Earlier
Jan'21: Our Gabriella paper has been awarded the best scientific paper award at ICPR 2020
|
|
|
|
|
Applied Scientist
Adobe Inc., Seattle, Washington, USA. Jan 2025 - Present
|
|
|
PhD AI/ML Intern
Apple Inc., Cupertino, California, USA. May 2024- Aug 2024
|
|
|
Research Scientist/ Engineer Intern
Adobe Inc., San Jose, California, USA. May 2023- Nov 2023 Host: Simon Jenni, Fabian Caba
|
|
|
Research Scientist Intern
Adobe Inc., Remote, USA. May 2022 - Nov 2022 Host: Simon Jenni
|
|
I have a broad interest in computer vision and machine learning. My primary research focuses on video understanding: self/semi supervised learning and action recognition.
My recent research also includes enhancing the fine-grained video understanding of the large foundational models and improving multi-modal generative AI for image editing applications. I have also worked on various robotics-related vision tasks like event-camera-based action recognition and drone-to-drone detections from videos.
|
|
|
Ishan Rajendrakumar Dave*, Tejas Panambur*, Chongjian Ge, Ersin Yumer, Xue Bai ArXiv Preprint, 2025 *= equal contribution
Modern text-to-video (T2V) diffusion models can synthesize visually compelling clips, yet they remain brittle at fine-scale structure: even state-of-the-art generators often produce distorted faces and hands, warped backgrounds, and temporally inconsistent motion. Such severe structural artifacts also appear in very low-quality real-world videos. Classical video restoration and super-resolution (VR/VSR) methods, in contrast, are tuned for synthetic degradations such as blur and downsampling and tend to stabilize these artifacts rather than repair them, while diffusion-prior restorers are usually trained on photometric noise and offer little control over the trade-off between perceptual quality and fidelity.
|

|
Animesh Gupta, Jay Parmar, Ishan Rajendrakumar Dave, Mubarak Shah Conference on Neural Information Processing Systems (NeurIPS) , 2025 Composed Video Retrieval (CoVR) retrieves a target video given a query video and a modification text describing the intended change. Existing CoVR benchmarks emphasize appearance shifts or coarse event changes and therefore do not test the ability to capture subtle, fast-paced temporal differences. We introduce TF-CoVR, the first large-scale benchmark dedicated to temporally fine-grained CoVR. TF-CoVR focuses on gymnastics and diving and provides 180K triplets drawn from FineGym and FineDiving. |
|
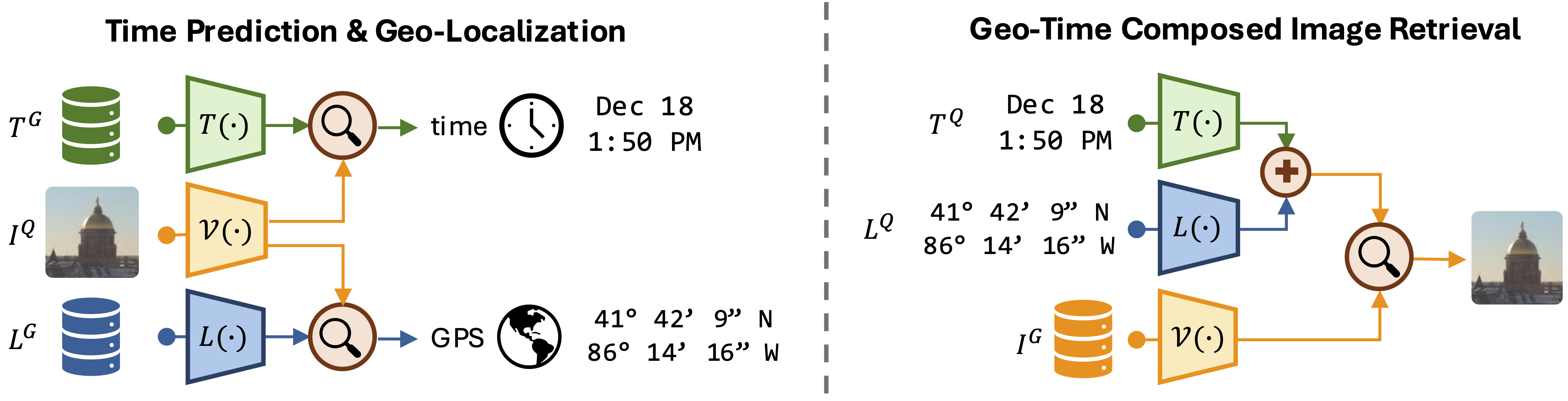
David Shatwell, Ishan Rajendrakumar Dave, Sirnam Swetha, Mubarak Shah International Conference on Computer Vision (ICCV) , 2025 Oral presentation! (Top 0.6% papers) Timestamp prediction aims to determine when an image was captured using only visual information, supporting applications such as metadata correction, retrieval, and digital forensics. To address the interdependence between time and location, we introduce GT-Loc, a novel retrieval-based method that jointly predicts the capture time (hour and month) and geo-location (GPS coordinates) of an image. Our approach employs separate encoders for images, time, and location, aligning their embeddings within a shared high-dimensional feature space. |
|
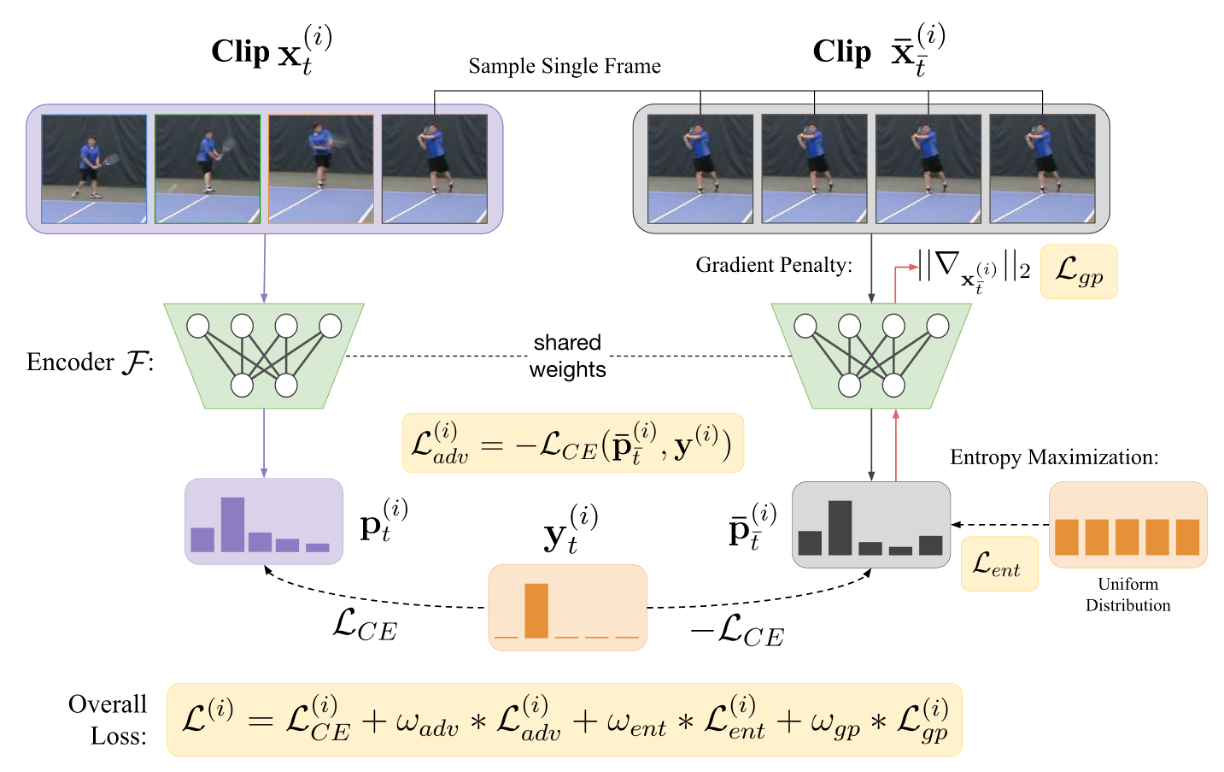
Joseph Fioresi, Ishan Rajendrakumar Dave, Mubarak Shah International Conference on Learning Representations (ICLR) , 2025 Poster Presentation We propose ALBAR, an adversarial learning approach to mitigate biases in action recognition. Our method addresses the challenge of spurious correlations between visual features and action labels that can lead to biased model predictions. |
|
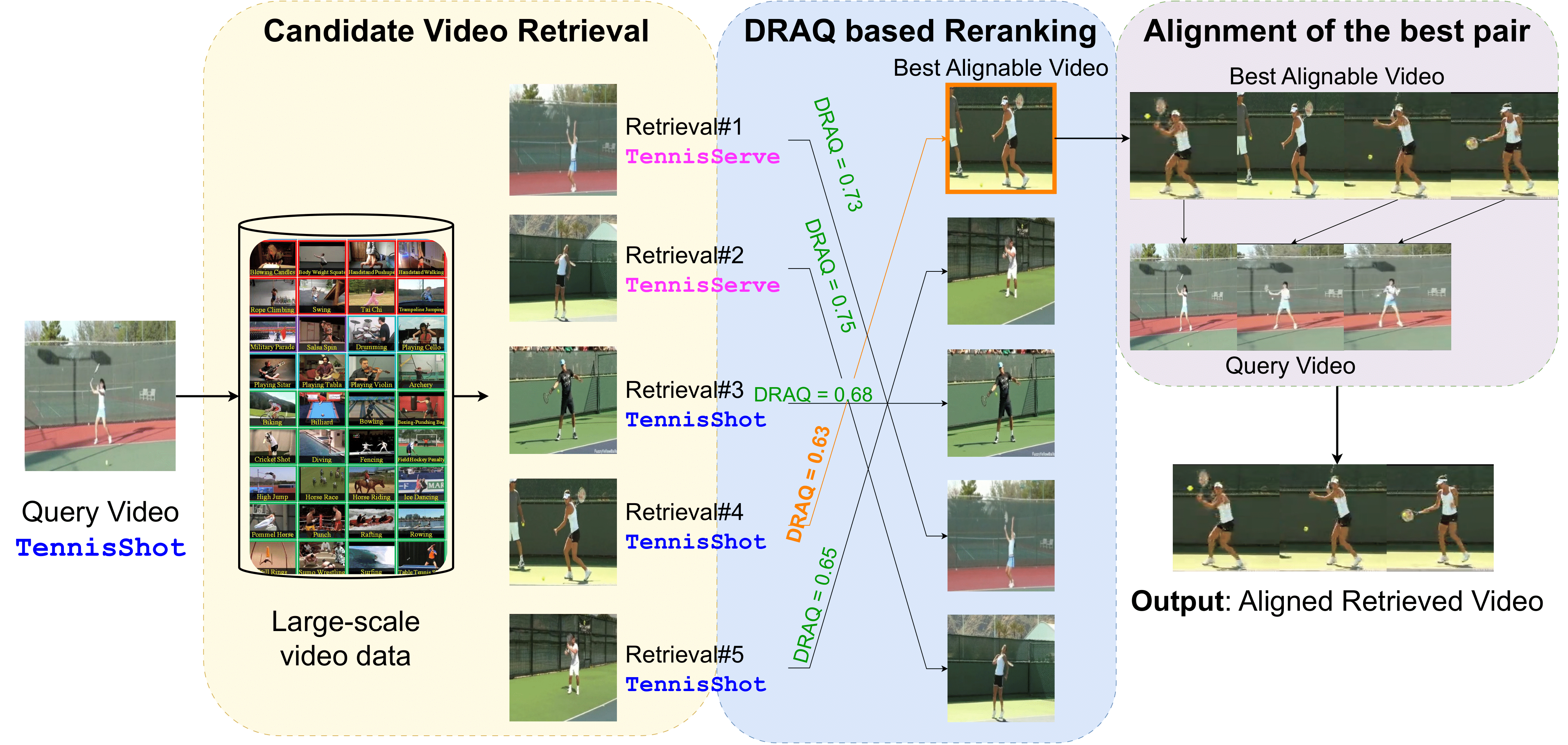
Ishan Rajendrakumar Dave, Fabian Caba, Mubarak Shah, Simon Jenni. The 18th European Conference on Computer Vision (ECCV) , 2024 Oral presentation! (Top 3% of accepted papers) Temporal video alignment synchronizes key events like object interactions or action phase transitions in two videos, benefiting video editing, processing, and understanding tasks. Existing methods assume a given video pair, limiting applicability. We redefine this as a search problem, introducing Alignable Video Retrieval (AVR), which identifies and synchronizes well-alignable videos from a large collection. Key contributions include DRAQ, a video alignability indicator, and a generalizable frame-level video feature design. |

|
Ishan Rajendrakumar Dave, Mamshad Nayeem Rizve, Mubarak Shah. The 18th European Conference on Computer Vision (ECCV) , 2024 We introduce Alignability-Verification-based Metric learning for semi-supervised fine-grained action recognition. Using dynamic time warping (DTW) for action-phase-aware comparison, our learnable alignability score refines pseudo-labels of the video encoder. Our framework, FinePseudo, outperforms prior methods on fine-grained action recognition datasets. Additionally, it demonstrates robustness in handling novel unlabeled classes in open-world setups. |
|
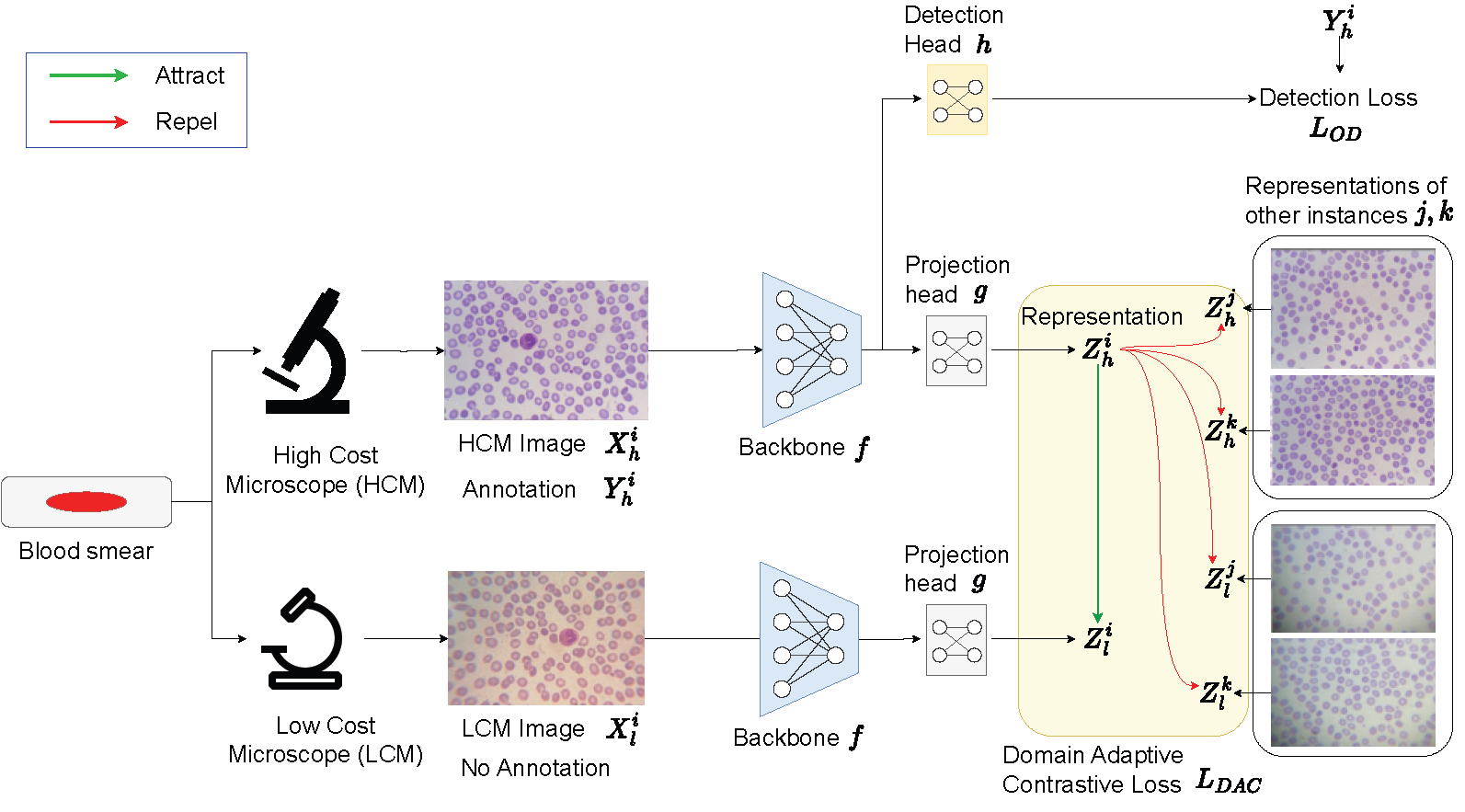
Ishan Rajendrakumar Dave, Tristan de Blegiers, Chen Chen, Mubarak Shah. 31st IEEE International Conference on Image Processing (ICIP) , 2024 Oral presentation! We propose a Domain Adaptive Contrastive objective to bridge the gap between High and Low Cost Microscopes. On the publicly available large-scale M5 dataset, our proposed method shows a significant improvement of 16% over the state-of-the-art methods in terms of the mean average precision metric (mAP), provides a 21× speed-up during inference, and requires only half as many learnable parameters as the prior methods. |
|
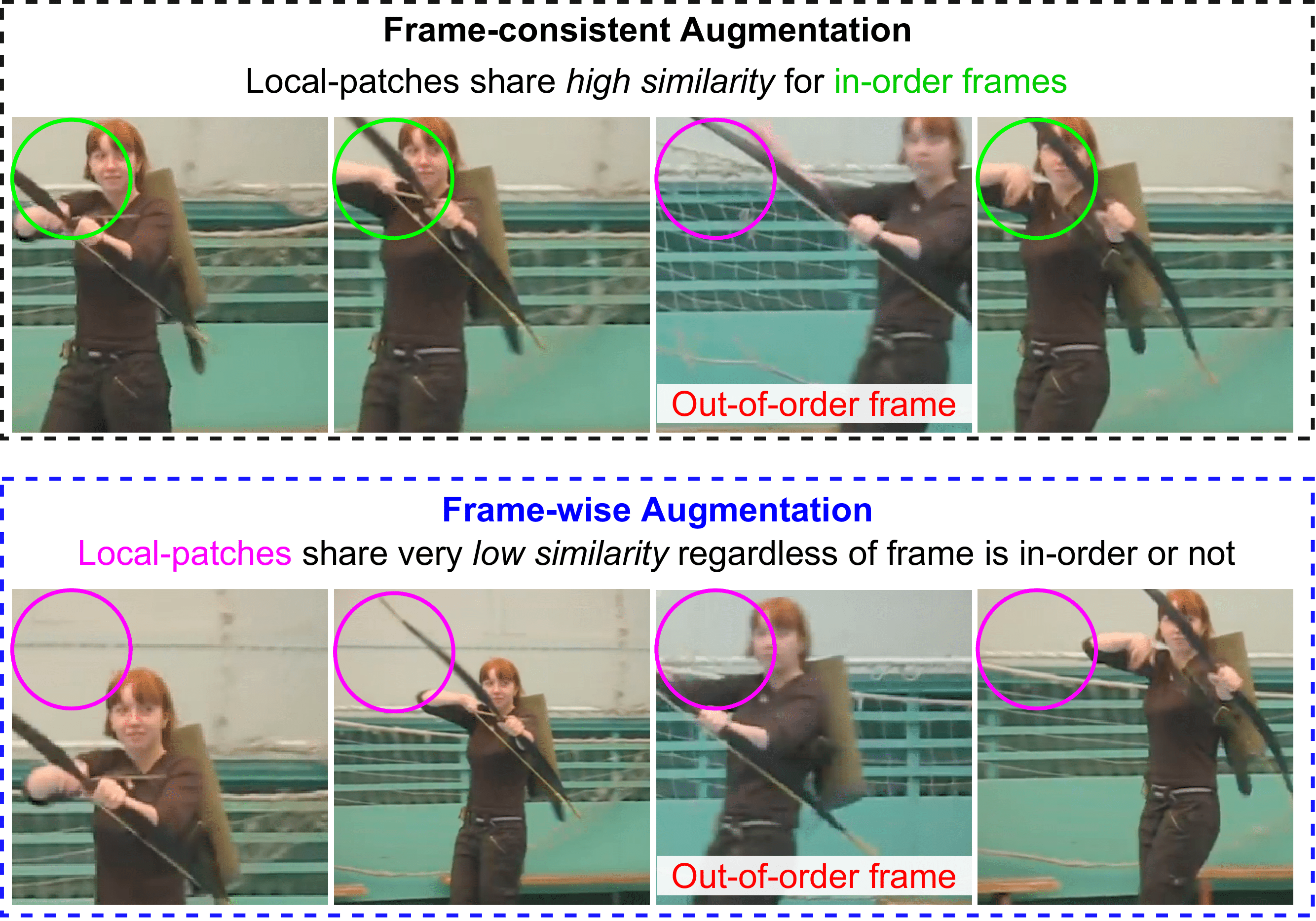
Ishan Rajendrakumar Dave, Simon Jenni, Mubarak Shah. AAAI Conference on Artificial Intelligence, Main Technical Track (AAAI) , 2024 We demonstrate experimentally that our more challenging frame-level task formulations and the removal of shortcuts drastically improve the quality of features learned through temporal self-supervision. Our extensive experiments show state-of-the-art performance across 10 video understanding datasets, illustrating the generalization ability and robustness of our learned video representations. |
|
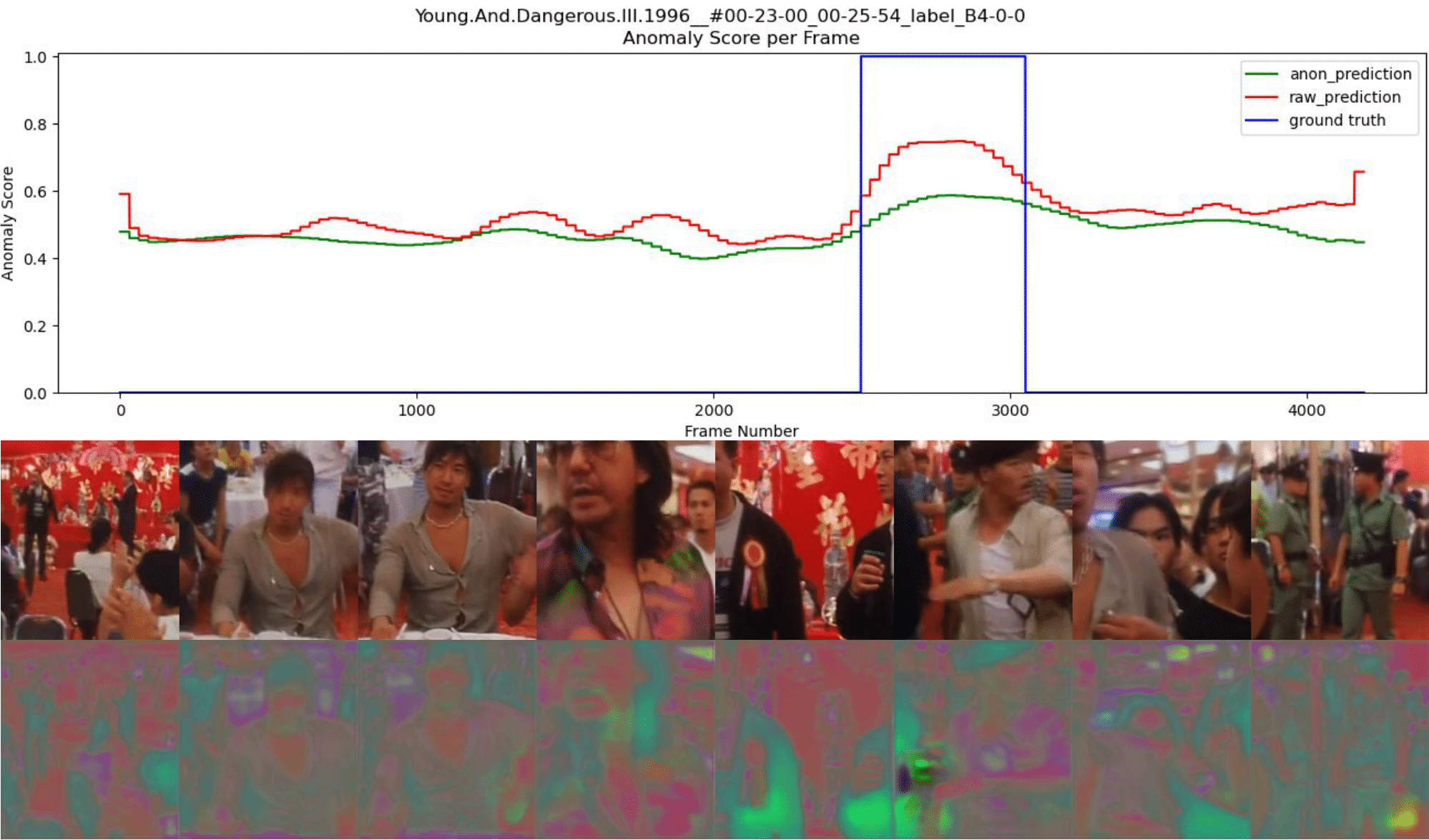
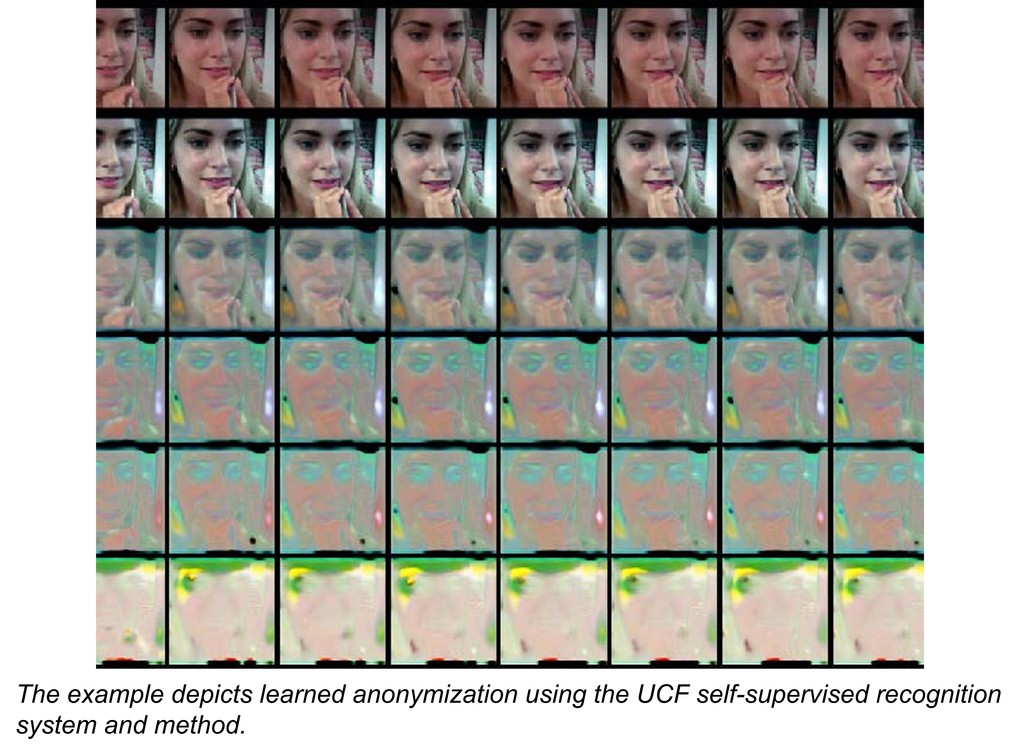
Joseph Fioresi, Ishan Rajendrakumar Dave, Mubarak Shah. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023 We propose TeD-SPAD, a privacy-aware video anomaly detection framework that destroys visual private information in a self-supervised manner. In particular, we propose the use of a temporally-distinct triplet loss to promote temporally discriminative features, which complements current weakly-supervised VAD methods. |
|
|
Tristan de Blegiers*, Ishan Rajendrakumar Dave*, Adeel Yousaf, Mubarak Shah. *= equal contribution IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023 We propose a video transformer-based framework for event-camera based action recognition, which leverages event-contrastive loss and augmentations to adapt the network to event data. Our method achieved state-of-the-art results on N-EPIC Kitchens dataset and competitive results on the standard DVS Gesture recognition dataset, while requiring less computation time compared to competitive prior approaches. |
|
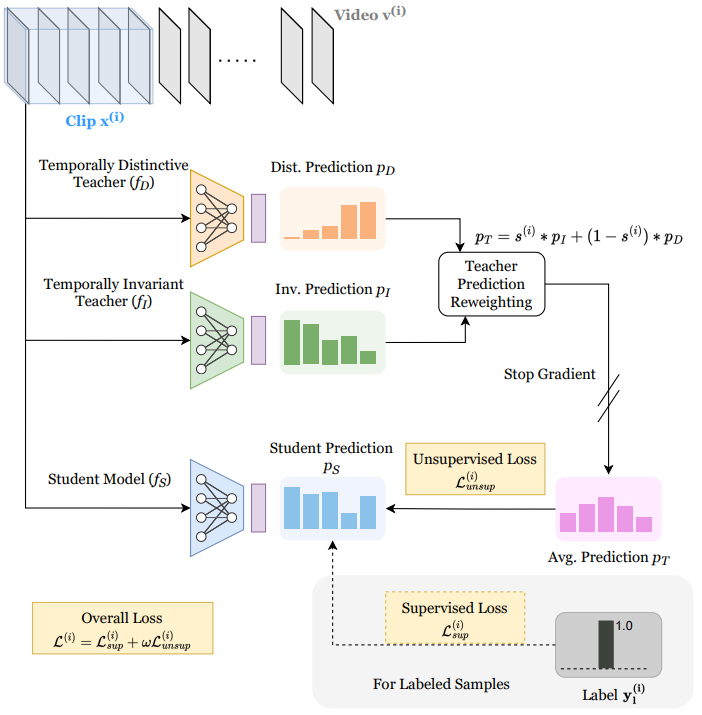
Ishan Rajendrakumar Dave, Mamshad Nayeem Rizve, Chen Chen, Mubarak Shah. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023 We propose a student-teacher semi-supervised learning framework, where we distill knowledge from a temporally-invariant and temporally-distinctive teacher. Depending on the nature of the unlabeled video, we dynamically combine the knowledge of these two teachers based on a novel temporal similarity-based reweighting scheme. State-of-the-art results on Kinetics400, UCF101, HMDB51. |
|
|
Tushar Sangam, Ishan Rajendrakumar Dave, Waqas Sultani, Mubarak Shah. 2023 IEEE International Conference on Robotics and Automation (ICRA), 2023 We propose a simple yet effective framework, TransVisDrone, that provides an end-to-end solution with higher computational efficiency. We utilize CSPDarkNet-53 network to learn object-related spatial features and VideoSwin model to improve drone detection in challenging scenarios by learning spatio-temporal dependencies of drone motion. |
|
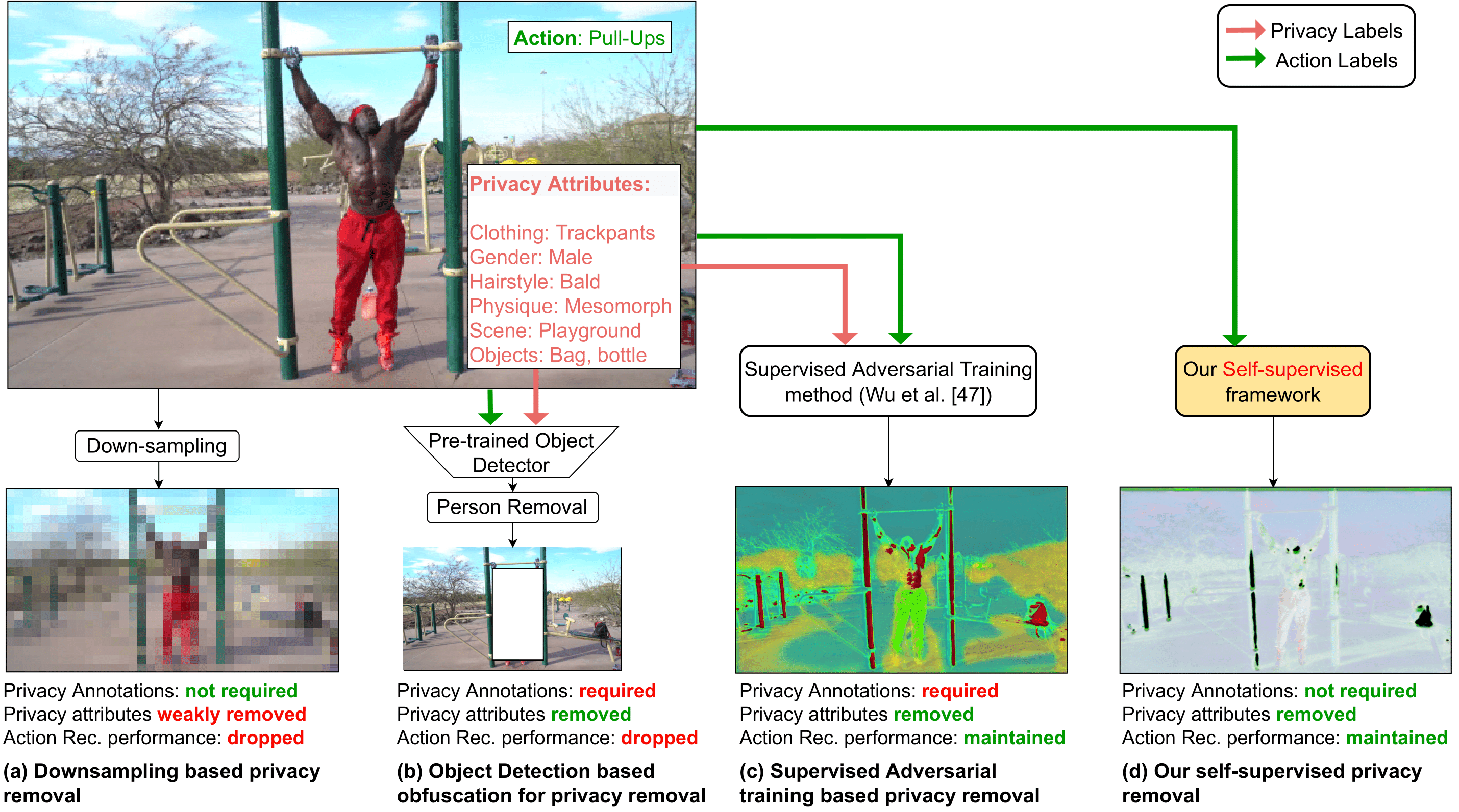
Ishan Rajendrakumar Dave, Chen Chen, Mubarak Shah. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022 For the first time, we present a novel training framework that removes privacy information from input video in a self-supervised manner without requiring privacy labels. We train our framework using a minimax optimization strategy to minimize the action recognition cost function and maximize the privacy cost function through a contrastive self-supervised loss. |
|
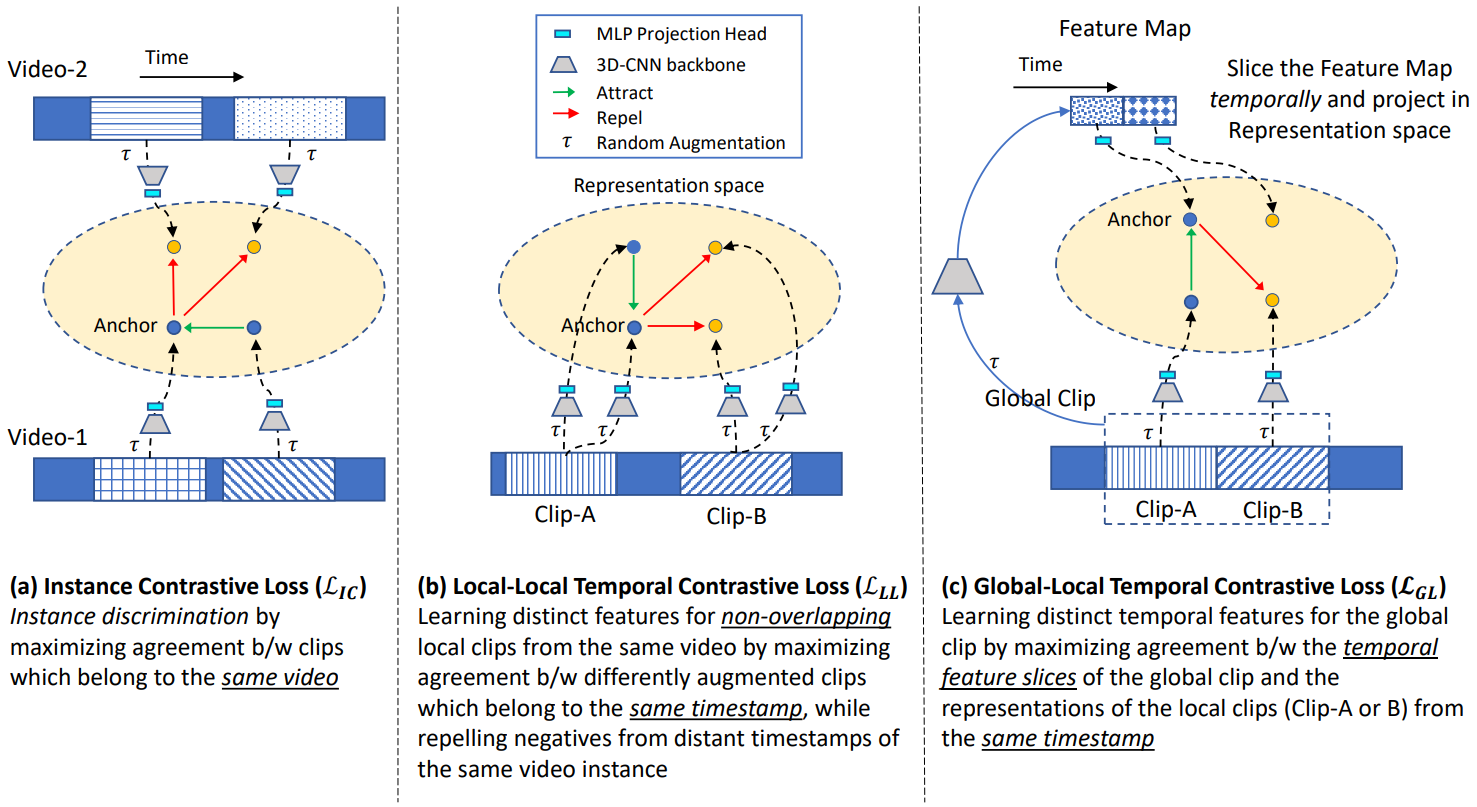
Ishan Dave, Rohit Gupta, Mamshad Nayeem Rizve, Mubarak Shah. Computer Vision and Image Understanding (CVIU), 2022 (250+ citations, Among the top-10 most downloaded papers in CVIU) We propose a new temporal contrastive learning framework for self-supervised video representation learning, consisting of two novel losses that aim to increase the temporal diversity of learned features. The framework achieves state-of-the-art results on various downstream video understanding tasks, including significant improvement in fine-grained action classification for visually similar classes. |

|
Ishan Dave, Zacchaeus Scheffer, Akash Kumar, Sarah Shiraz, Yogesh Singh Rawat, Mubarak Shah. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2022 We propose a realtime, online, action detection system which can generalize robustly on any unknown facility surveillance videos. We tackle the challenging nature of action classification problem in various aspects like handling the class-imbalance training using PLM method and learning multi-label action correlations using LSEP loss. In order to improve the computational efficiency of the system, we utilize knowledge distillation. |
|
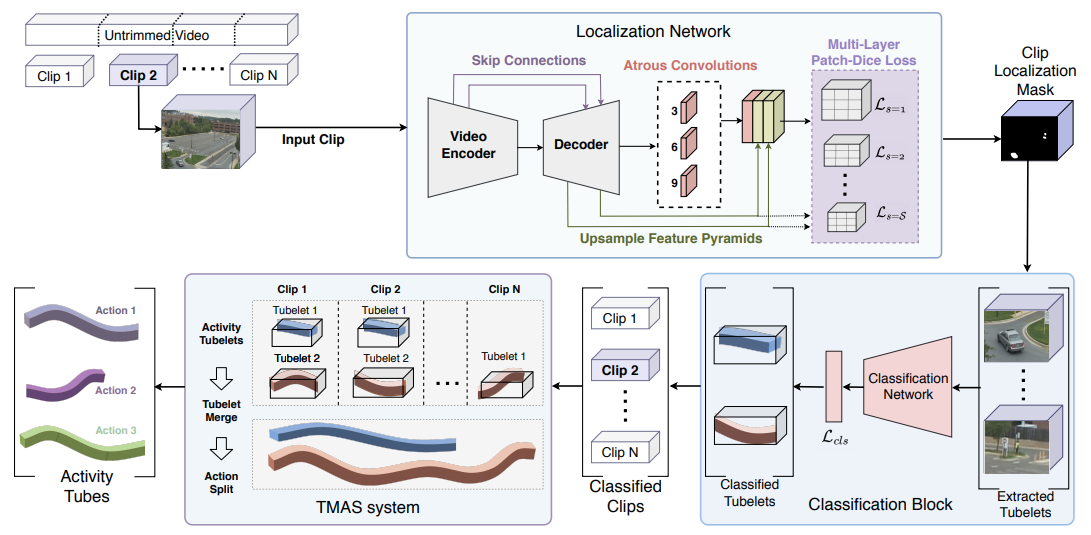
Mamshad Nayeem Rizve, Ugur Demir, Praveen Tirupattur, Aayush Jung Rana, Kevin Duarte, Ishan R Dave, Yogesh S Rawat, Mubarak Shah. 25th International Conference on Pattern Recognition (ICPR), 2021 (Best Paper Award) Gabriella consists of three stages: tubelet extraction, activity classification, and online tubelet merging. Gabriella utilizes a localization network for tubelet extraction, with a novel Patch-Dice loss to handle variations in actor size, and a Tubelet-Merge Action-Split (TMAS) algorithm to detect activities efficiently and robustly. |
|
|



{kind=link}